当前的 IntelliJ IDEA 设置的编码为 GBK 编码 ,
选择 " 菜单栏 / File / Settings " 选项 ,
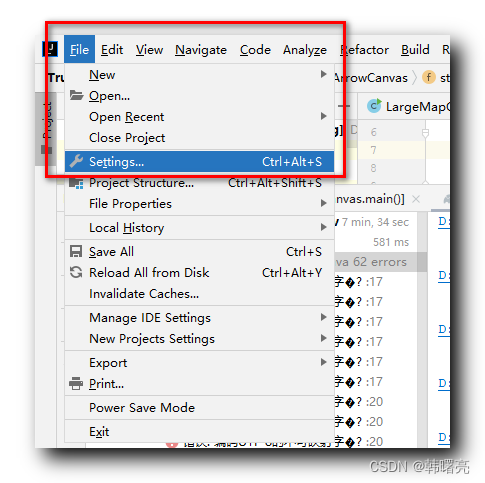 在这里插入图片描述
在这里插入图片描述在 " File Encodings " 中 , 查看 工程的编码 ,
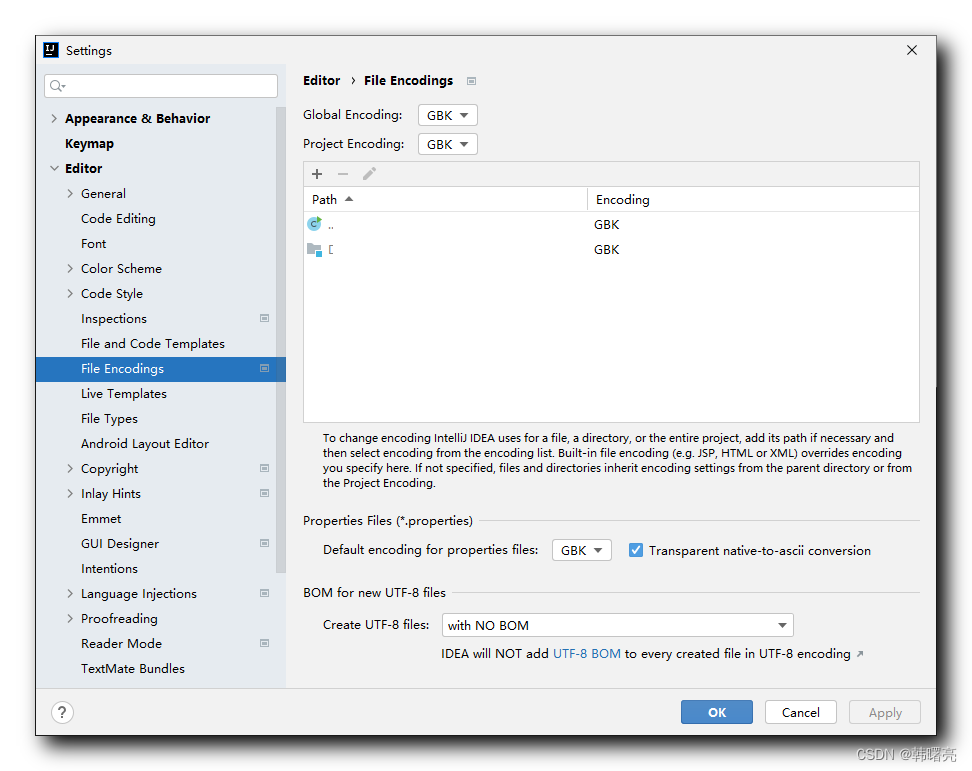 在这里插入图片描述
在这里插入图片描述运行时报错 : 在中文注释的位置 , 编码报错 ;
D:\002_Project\003_Java_Work\Exsample\src\main\java\ArrowCanvas.java:17: 错误: 编码UTF-8的不可映射字�? // ����ֱ�� ^ D:\002_Project\003_Java_Work\Exsample\src\main\java\ArrowCanvas.java:17: 错误: 编码UTF-8的不可映射字�? // ����ֱ�� ^ D:\002_Project\003_Java_Work\Exsample\src\main\java\ArrowCanvas.java:17: 错误: 编码UTF-8的不可映射字�? // ����ֱ�� ^ D:\002_Project\003_Java_Work\Exsample\src\main\java\ArrowCanvas.java:17: 错误: 编码UTF-8的不可映射字�?
二、 解决方案在 Windows 环境下的 IntelliJ IDEA 中 , 使用 GBK 编码 , 运行程序是不会出错的 ;
命令行默认的编码为 UTF-8 编码 , 如果在 命令行 中运行 GBK 编码 的 程序 , 如果项目中有中文注释 , 或者打印中文内容 , 就会出现
错误: 编码UTF-8的不可映射字�?报错信息 ;
如果是在 命令行中 编译运行 GBK 编码的 Java 源代码 , 使用如下命令 :
javac -encoding GBK Example.javajava -Dfile.encoding=GBK Example在 javac 编译命令中 , 使用 -encoding GBK 指定了编译过程中使用 GBK 编码进行编译 ;在 java 执行命令中 , 使用 -Dfile.encoding=GBK 指定执行程序的编码为 GBK 编码 ;如果是在 IntelliJ IDEA 环境中 , 选择 " Edit Configurations… " 选项 ,
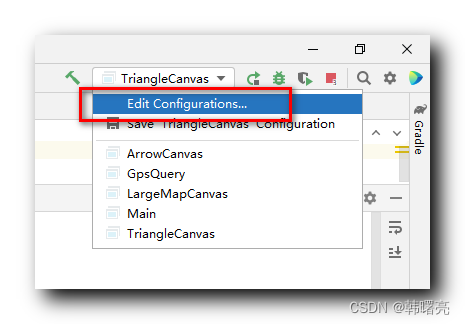 在这里插入图片描述
在这里插入图片描述在弹出的 " Run/Debug Configurations " 配置对话框中 , 勾选 Modify options 选项 , 在新增的 " VM options " 对话框中 , 输入
-Dfile.encoding=GBK内容 ;
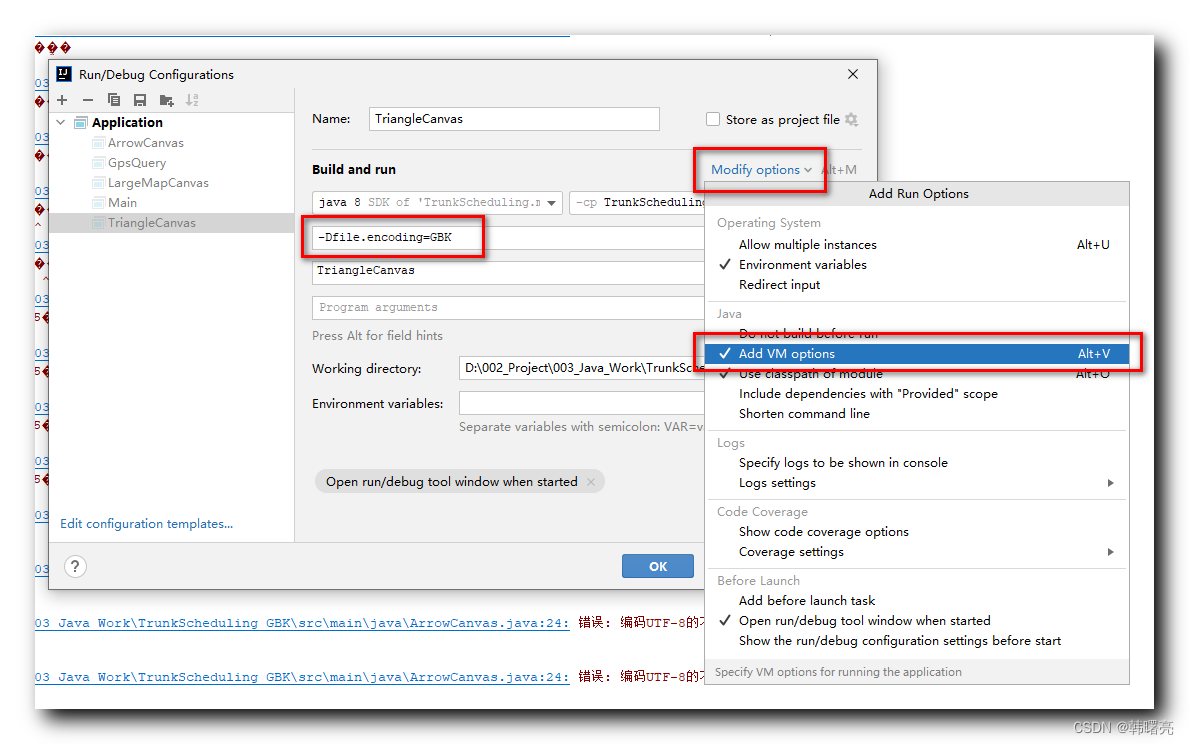 在这里插入图片描述
在这里插入图片描述经过上面的设置后 , 再次运行程序 , 就不会出现 错误: 编码UTF-8的不可映射字�? 错误信息了 ;